Leveraging Advanced Indexing Techniques in AI Search Solutions
In the rapidly evolving field of artificial intelligence, the capability to efficiently search and retrieve relevant information from vast datasets is crucial. This capability underpins many AI applications, from chatbots to recommendation systems. A core component of these systems is the Retrieval-Augmented Generation (RAG) pipeline, which hinges significantly on the quality of the search index.
Understanding the Vector Store Index
At the heart of modern search solutions within AI applications lies the vector store index. This index stores vectorized content from source data, which is then used to match queries with the most relevant information. The process begins with the vectorization of a query, where it is transformed into a vector representation that can be compared against indexed vectors.
Index Types and Their Implications
1. Naive Implementation:
The simplest form of indexing involves a flat index where the distance between the query vector and every vector in the dataset is calculated—a brute-force approach that is computationally expensive and inefficient for large datasets.
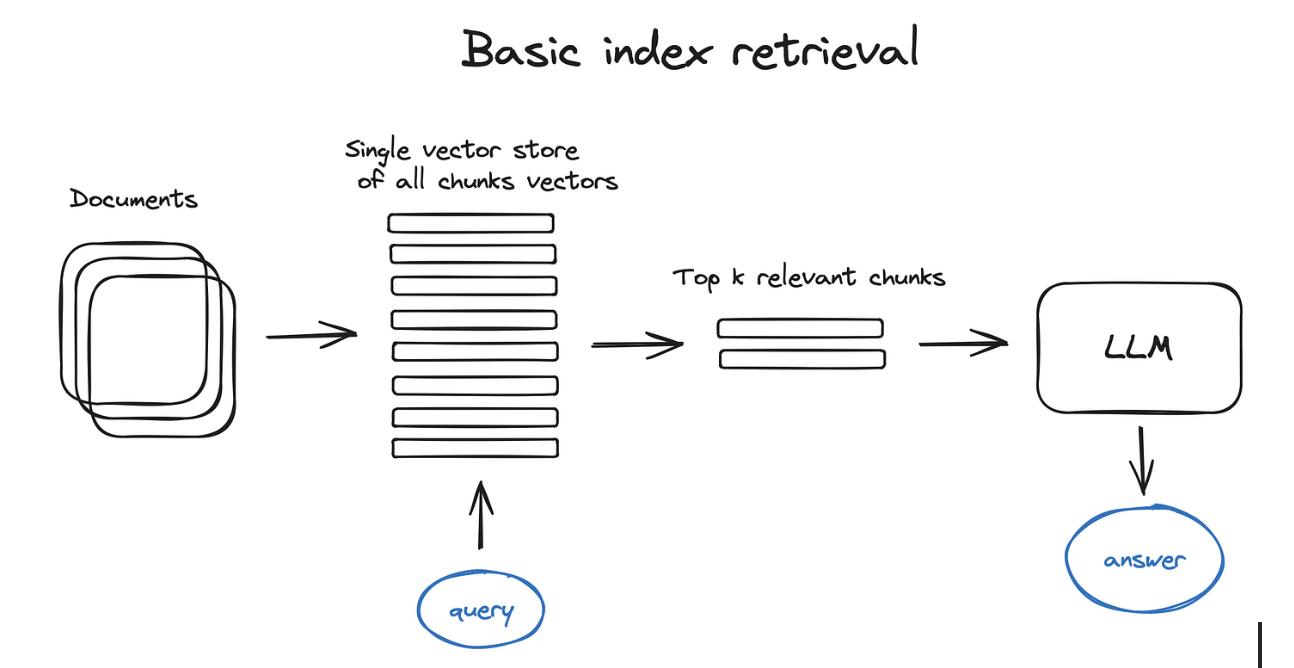
2. Optimized Search Indices:
For better performance, especially with datasets exceeding 10,000 elements, advanced indices like faiss, nmslib, or annoy are utilized. These employ Approximate Nearest Neighbours (ANN) algorithms, which use techniques like clustering, trees, or Hierarchical Navigable Small World (HNSW) graphs to quickly zero in on the most relevant vectors.
3. Managed Solutions:
Platforms like OpenSearch, ElasticSearch, and vector databases such as Pinecone, Weaviate, and Chroma manage the entire data ingestion pipeline, simplifying the deployment and maintenance of search indices.
4. Specialized Indices:
For scenarios requiring fine-tuned searches, metadata can be stored alongside vectors. This allows for filtering based on specific criteria like dates or sources, enhancing the precision of the retrieval process.
Hierarchical Indices and Hybrid Approaches
The sophistication of search indices is not just about managing large volumes of data but also about enhancing the relevance and precision of the information retrieved.
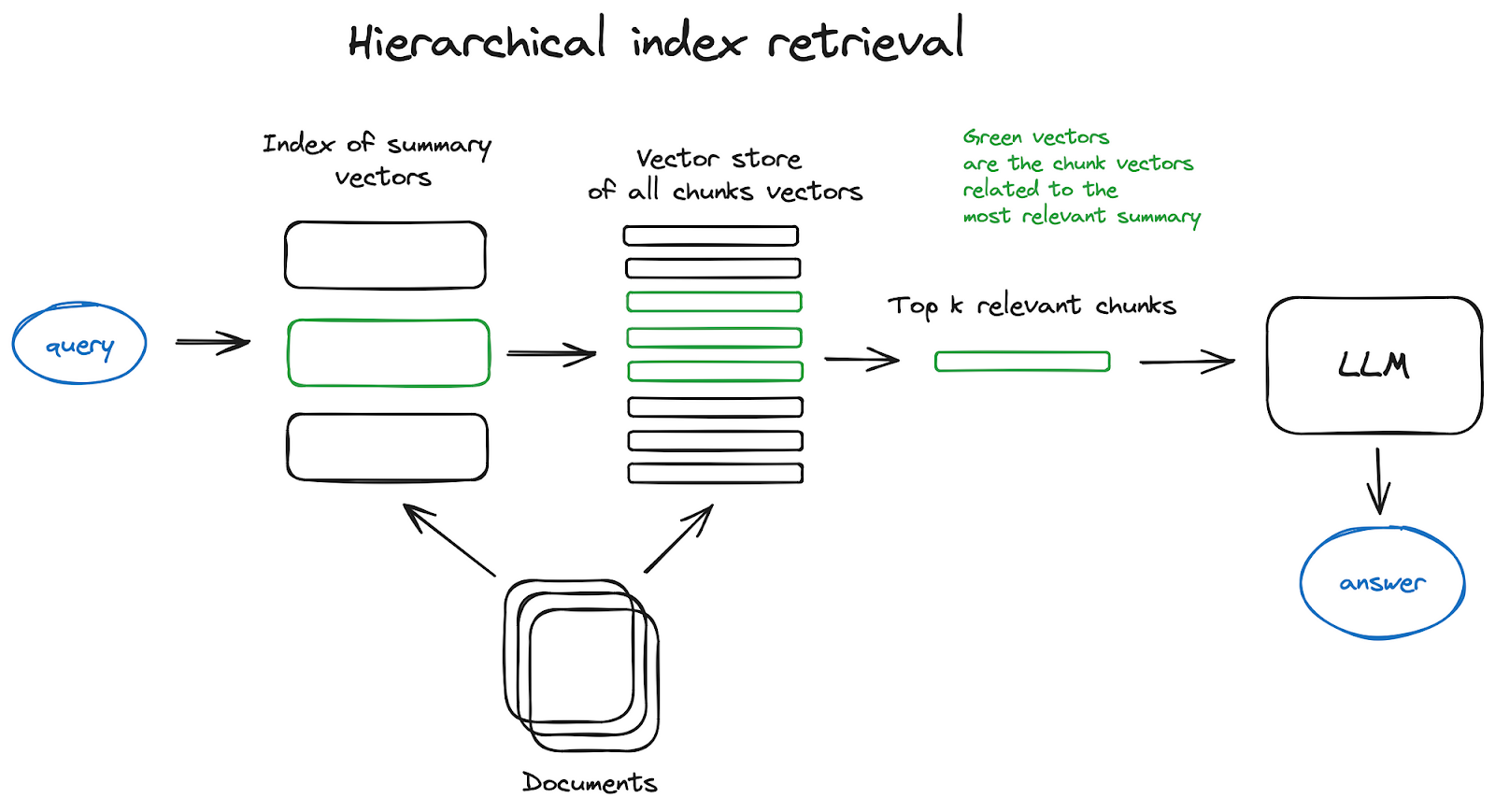
1. Hierarchical Indices:
By creating dual indices — one for summaries and another for detailed document chunks — AI systems can perform a two-step retrieval process. This involves initially filtering documents based on summaries and subsequently delving deeper into the selected documents for detailed information.
2. Hypothetical Question Indexing (HyDE):
An innovative approach involves having an LLM generate hypothetical questions from each chunk and indexing these questions. This method significantly improves semantic similarity between the query and the content, enhancing the search quality.
3. Context Enrichment Strategies:
3.1 Sentence Window Retrieval:
Each sentence is independently vectorized, allowing for precise matches. The context is then broadened by retrieving additional sentences surrounding the matched sentence, providing a richer base for the AI to generate responses.

The green part is the sentence embedding found while search in index, and the whole black + green paragraph is fed to the LLM to enlarge its context while reasoning upon the provided query
3.2 Auto-merging Retriever:
This method involves splitting documents into hierarchical chunks, retrieving the most relevant small chunks first, and then automatically merging them into larger chunks if they share a common parent. This process ensures that the context provided to the AI is comprehensive yet focused.
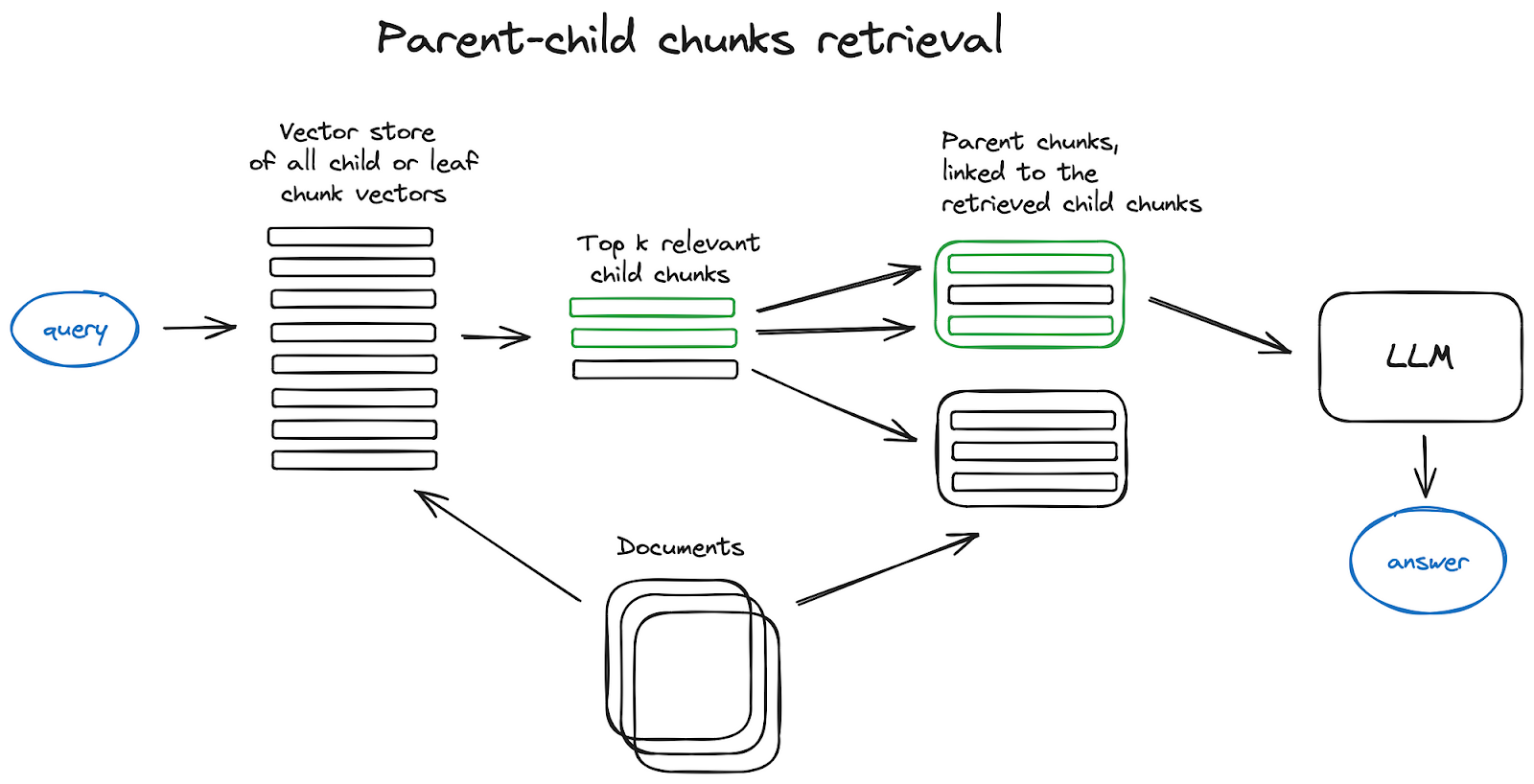
Documents are splitted into an hierarchy of chunks and then the smallest leaf chunks are sent to index. At the retrieval time we retrieve k leaf chunks, and if there is n chunks referring to the same parent chunk, we replace them with this parent chunk and send it to LLM for answer generation.
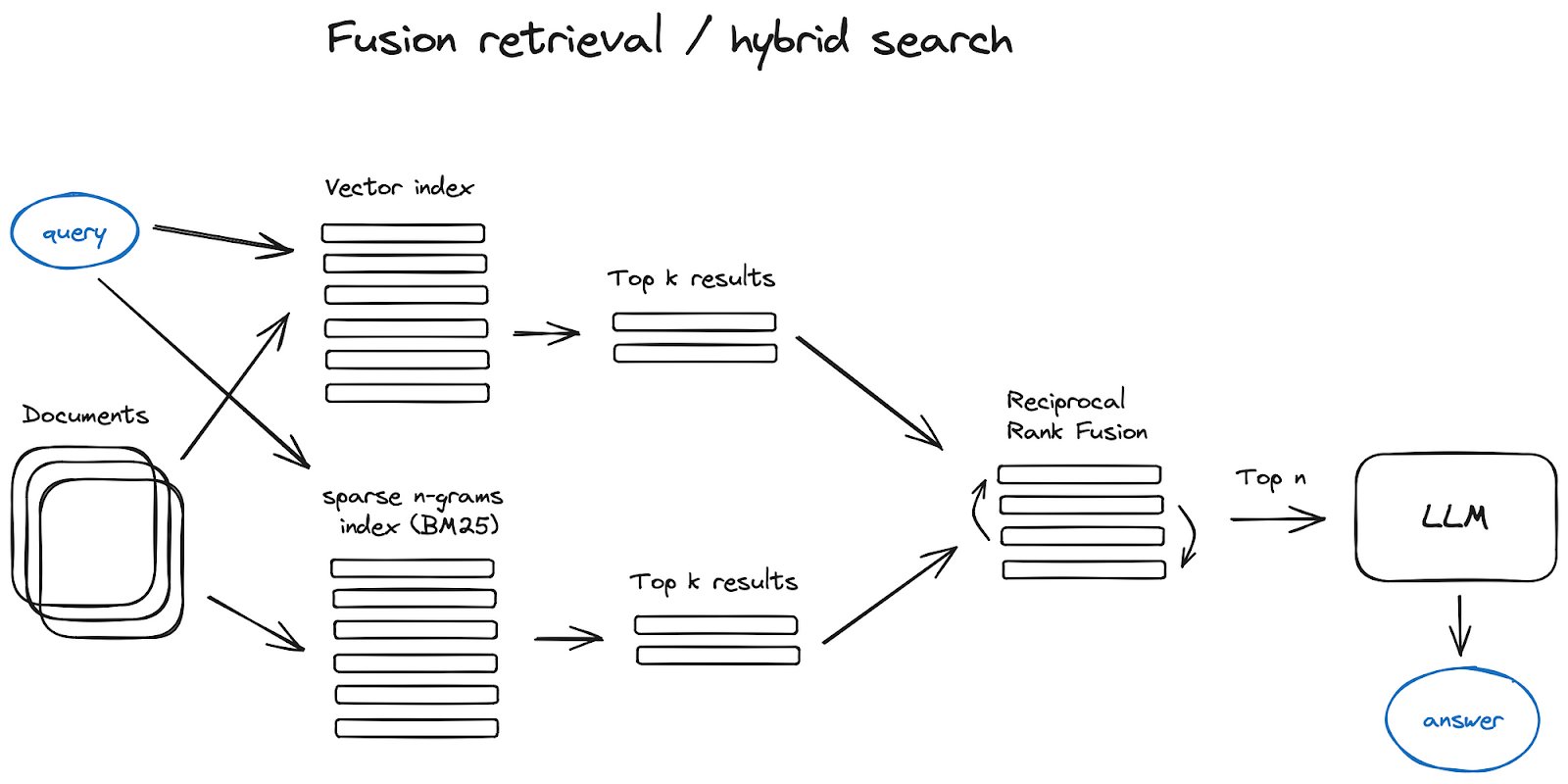
Fusion Retrieval: Combining Old and New
A fusion retrieval approach amalgamates traditional keyword-based search techniques (like tf-idf or BM25) with modern vector-based semantic search. By using algorithms like the Reciprocal Rank Fusion (RRF), these hybrid systems can optimize the retrieval process, leveraging the strengths of both methods to provide highly relevant results.
Conclusion
The development of sophisticated indexing techniques marks a significant advancement in the field of AI-driven search solutions. By carefully choosing and configuring these indices, developers can greatly enhance the efficiency and accuracy of AI applications, ensuring that they deliver timely and contextually relevant information. As technology evolves, the integration of more nuanced algorithms and hybrid approaches will likely become standard, pushing the boundaries of what AI can achieve in information retrieval.